OpenRouter routes requests to the best available providers for your model, given your preferences. By default, requests are load-balanced across the top providers to maximize uptime.
Use this node in your workflow instead of relying on a single LLM. Keep the same order for text-processing nodes, especially if you’re using multiple. This way, if one provider goes down, your system keeps running. The results may vary slightly or cost more at times, but your project stays reliable.
Change the model you want to use by configuring Models in the Processor. You can use models from OpenAI, Anthropic, Google, DeepSeek and more.
Parameters explanation
Credentials
Your unique authorization that provides access to OpenRouter’s features and models. There are Scade cewdintials available, but you can use your own if needed.
Models
A selection of AI models from various providers. Each model has specific strengths suited to different types of tasks.
Allow Fallbacks
Permits the system to switch to an alternative model if your first-choice model isn’t available, ensuring uninterrupted task completion.
Require Parameters
Ensures specific parameters (like temperature or max tokens) are always included in your requests, maintaining consistency across outputs.
Data Collection (Deny, Allow)
Controls whether OpenRouter collects interaction data for model improvement. Denying keeps interactions private, while allowing supports model enhancement.
Order
Defines a preferred sequence for using models from various providers, allowing the system to try them in order if your top choice isn’t available.
Messages
Contains the input you want the AI to process and can include previous messages to provide context for ongoing conversations.
Temperature
Adjusts the creativity level of responses. A higher temperature makes responses more varied, while a lower temperature keeps them straightforward and predictable.
Top P
Fine-tunes the probability distribution in word choice, where lower values select common words, and higher values allow more unusual choices.
Stop
Specifies where the AI should stop responding, helping you control the length or content boundaries of the response.
Max Tokens
Sets the maximum length of the AI’s response in tokens, balancing brevity and detail as needed.
Presence Penalty
Discourages repetition of ideas or topics, promoting more varied content within a single response.¬fkr
Frequency Penalty
Reduces repeated word use, enhancing vocabulary diversity and making responses less repetitive.
How to use on Scade
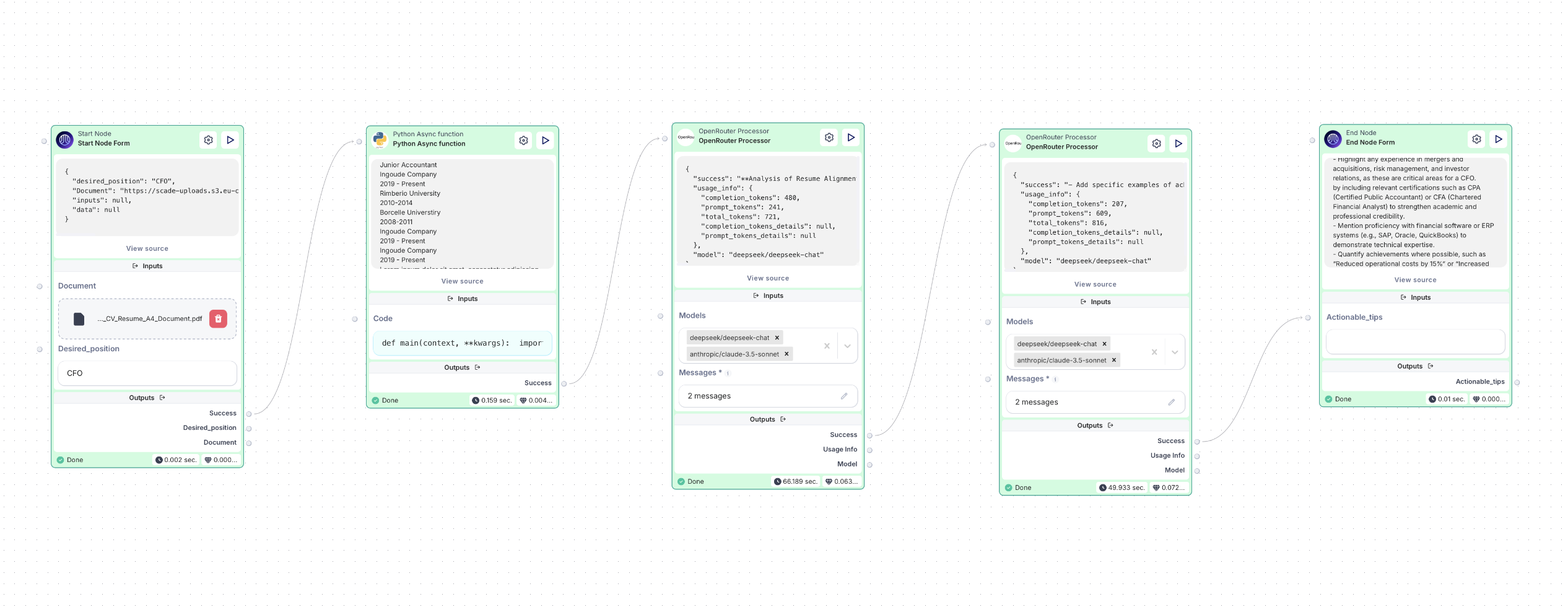
Case 1: Resume enhancement toolkit
Resume optimization by analyzing its alignment with a desired job position and providing actionable improvement tips.
How it works:
-
User Input: Upload a PDF/DOCX resume and specify the desired job title.
-
Text Extraction: The system extracts resume content for analysis using Python node.
-
AI-Powered Evaluation: The resume is compared against the target job using OpenRouter processor with chosen AI models, identifying missing skills, key improvements, and formatting suggestions.
-
Optimization Recommendations: Here OpenRouter node with choosen Ai models generates actionable tips, such as skill adjustments, phrasing enhancements, and formatting improvements.
-
Final Output: The user receives a personalized improvement report to optimize their resume for better job prospects.