Claude AI is a conversational artificial intelligence developed by Anthropic, designed to assist with tasks, answer questions, and engage in dialogue using natural language. It’s built to prioritize safe, informative, and user-friendly interactions, making it suitable for both casual and professional use cases.
-
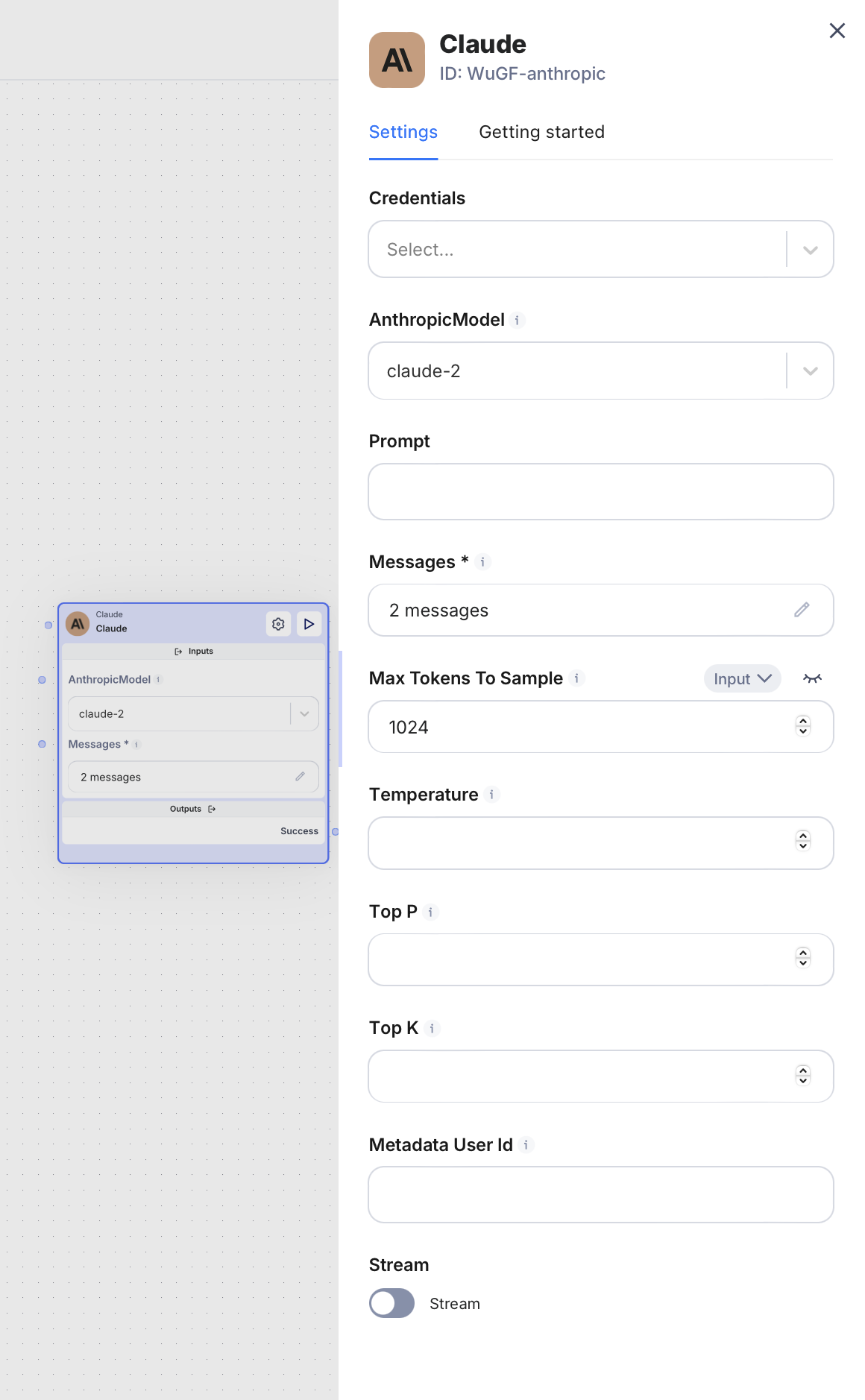
Credentials:
This is your authentication key or token that allows you to access the API. You can use Scade’s default or your own credentials to make requests to the Claude AI. -
Anthropic Models:
Anthropic offers several models, each with different capabilities and use cases:- Claude-2: A powerful, general-purpose model suitable for a wide range of tasks. It’s good for complex reasoning, analysis, and generation.
- Claude-instant-1: A faster, more lightweight version of Claude. It’s ideal for applications requiring quick responses, like chatbots or real-time interactions.
- Claude-3-opus-20240229: The most capable model, excellent for complex tasks, deep analysis, and sophisticated reasoning. Best for when you need the highest quality output.
- Claude-3-sonnet-20240229: A balanced model offering high capability with improved efficiency. Good for a wide range of tasks while being more cost-effective than Opus.
- Claude-3-5-sonnet-20240620: An updated version of Claude-3-sonnet, likely with improved capabilities or efficiency.
-
Prompt:
This is the text input you provide to the model. It can be a question, a statement, or any text you want the model to respond to or complete. -
Messages:
For chat-based interactions, you can provide a list of previous messages to give context to the conversation. -
Max Tokens to Sample:
This sets the maximum length of the model’s response in tokens (roughly words or word pieces). It helps control the length of the output. -
Temperature:
A value between 0 and 1 that controls the randomness of the output. Lower values (closer to 0) make the output more deterministic and focused, while higher values (closer to 1) make it more random and creative. -
Top P:
Also known as nucleus sampling, this parameter sets a probability threshold for token selection. It can help control the diversity of the output. -
Top K:
This parameter limits the number of highest probability tokens to consider at each step of generation. It’s another way to control output diversity. -
Metadata User ID:
This allows you to attach a user identifier to the request, which can be useful for tracking or personalization purposes. -
Stream:
If set to true, the node will return the response in chunks as it’s generated, rather than waiting for the entire response to be completed. This is useful for creating a more interactive experience.
How to use in Scade:
Setting up a simple flow with Claude
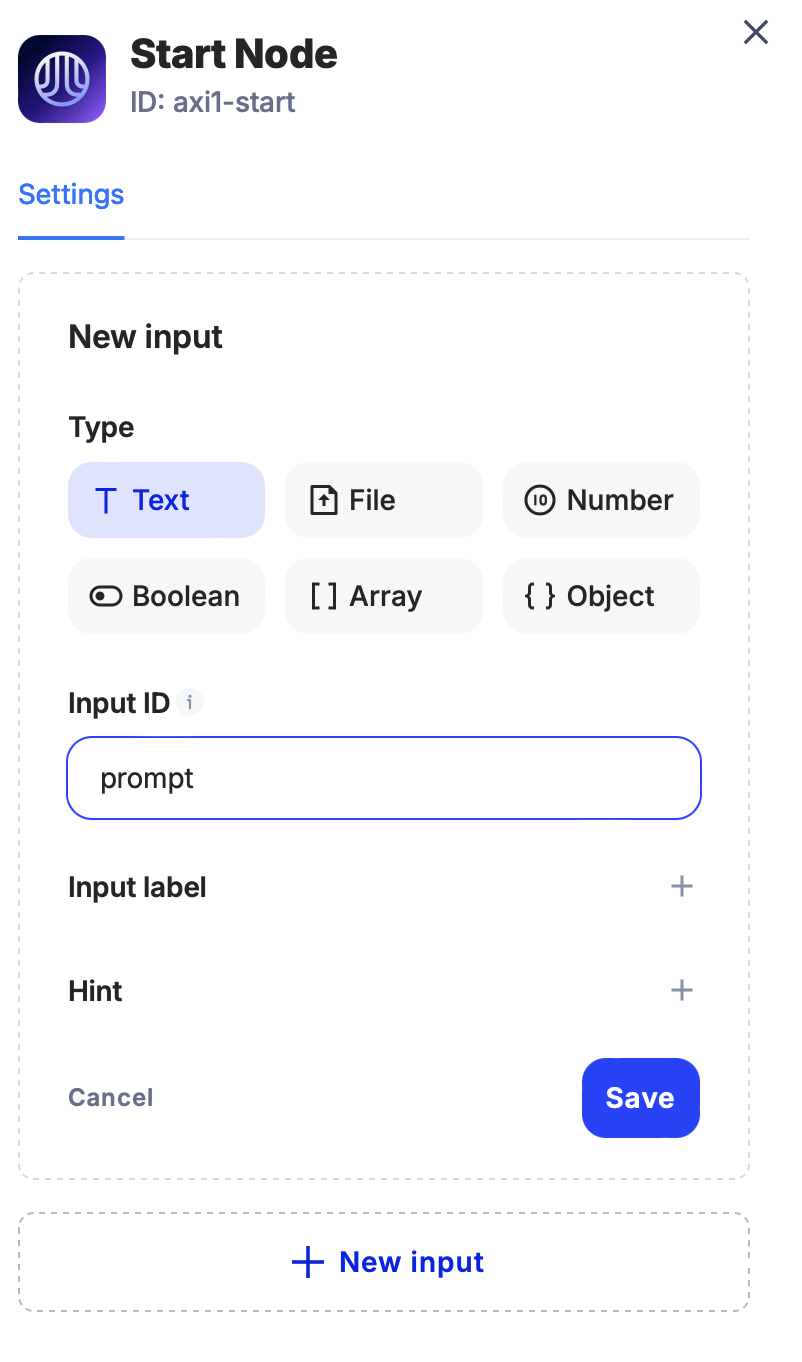
1. Configuring the Start node
First, let’s create an input text field in the Start node. This will allow us to enter a prompt.
2. Configuring the Claude node
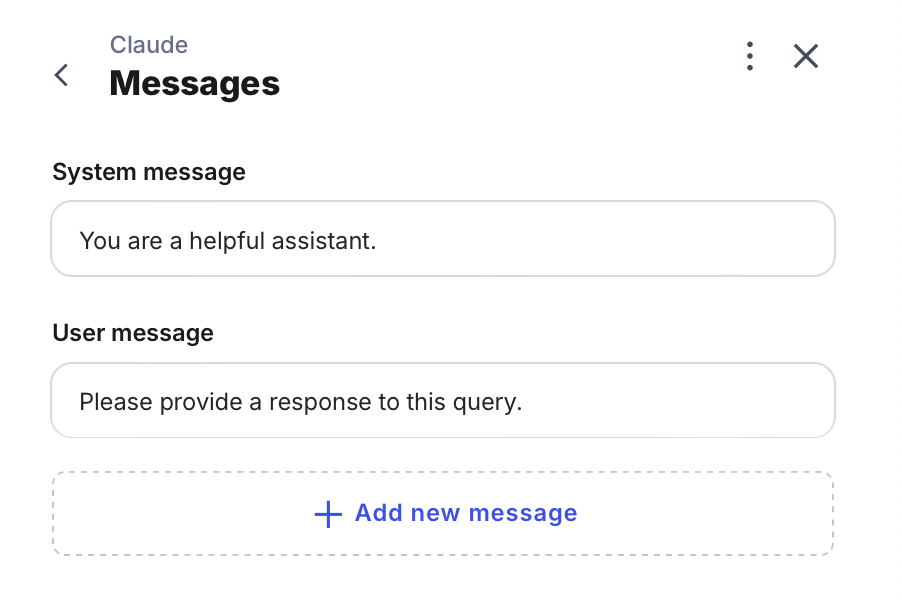
Please see ChatGPT tutorial for better understanding of roles purposes.
For your convenience, the node comes with pre-filled message fields.
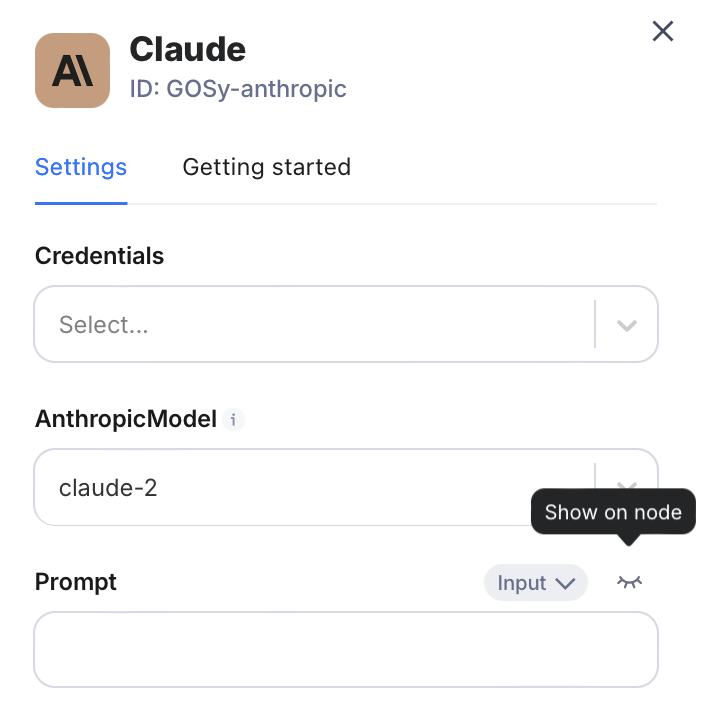
The Claude node includes a prompt field, which we’ll use to link it with input from our start node. If this field is initially hidden in the node configuration, click the eye icon next to it to make it visible.
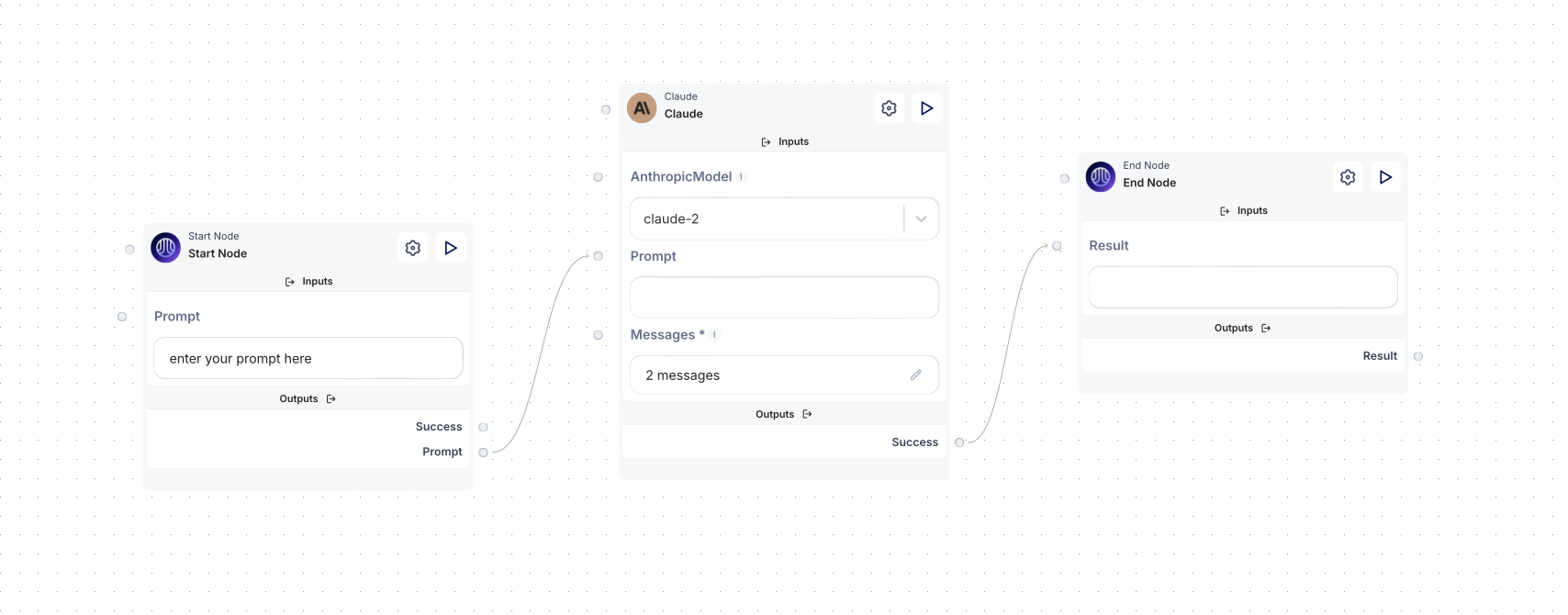
3. Connecting the nodes
Now that the nodes are configured, let’s connect the flow:
• First, connect the Start node prompt field to the Claude node by dragging the prompt circle to the Claude node’s prompt.
• Next, connect the success point of the Claude node to the End node result field to display the response.
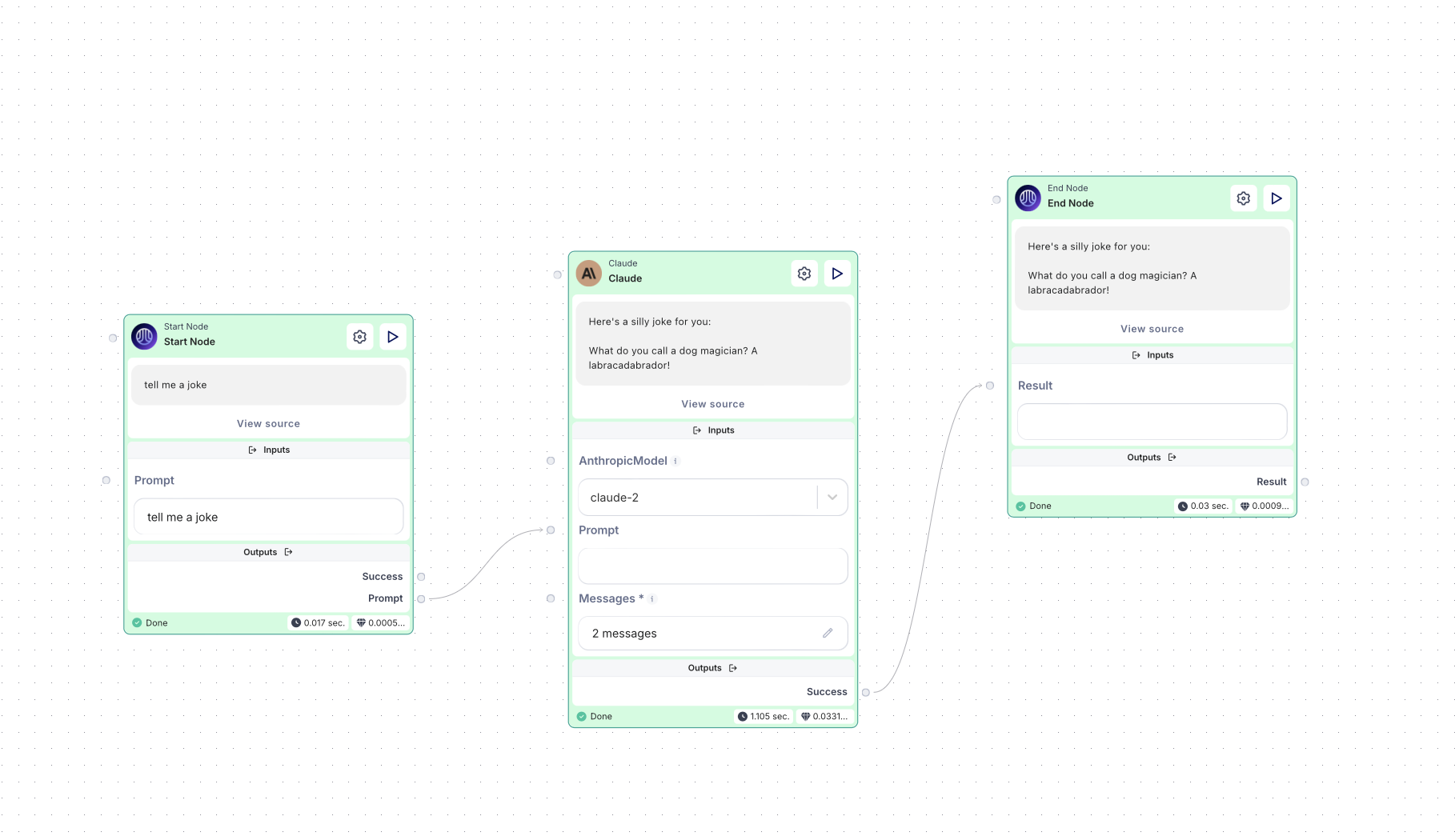
4. Testing the flow
It’s time to test the setup! Type “Tell me a joke” in the prompt field and press Start Flow at the top of the page.
And that’s it! Your flow is now working and should return a joke from Claude.
Here we go.
HINT:
For a beginner, the most important parameters to focus on initially would be:
- Model selection (based on your specific needs)
- Prompt (your input to the model)
- Max Tokens to Sample (to control response length)
- Temperature (to adjust between focused and creative outputs)