Level 2 - Subflow Cycle
In this tutorial, we’ll cover how to prepare a flow that processes an array of inputs, cycles through each item with a pre-defined subflow, and finally collects the results to analyze them using an LLM node. This is useful when you’re working with data that can be broken into chunks (like multiple YouTube videos or texts) and want to streamline the processing.
Let’s dive into the steps to get this up and running!
Step 1 - Prepare Sub-Workflow
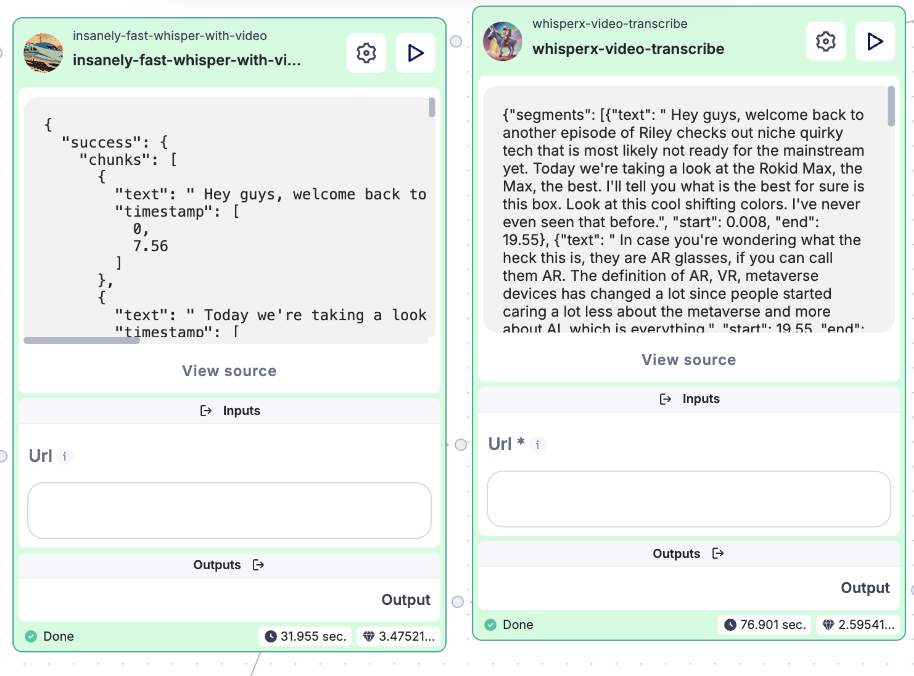
Since we will be analyzing a YouTube video in this example, we’re going to use a powerful node called insanely-fast-whisper-with-video. This node is specifically designed for fast video transcription, making it ideal for our use case of extracting plain text from YouTube videos.
We’ll be passing a YouTube link into this node, which will automatically extract and return the plain text of the video’s audio. The goal is to ensure that our sub-workflow takes care of the transcription so we can process the text later.
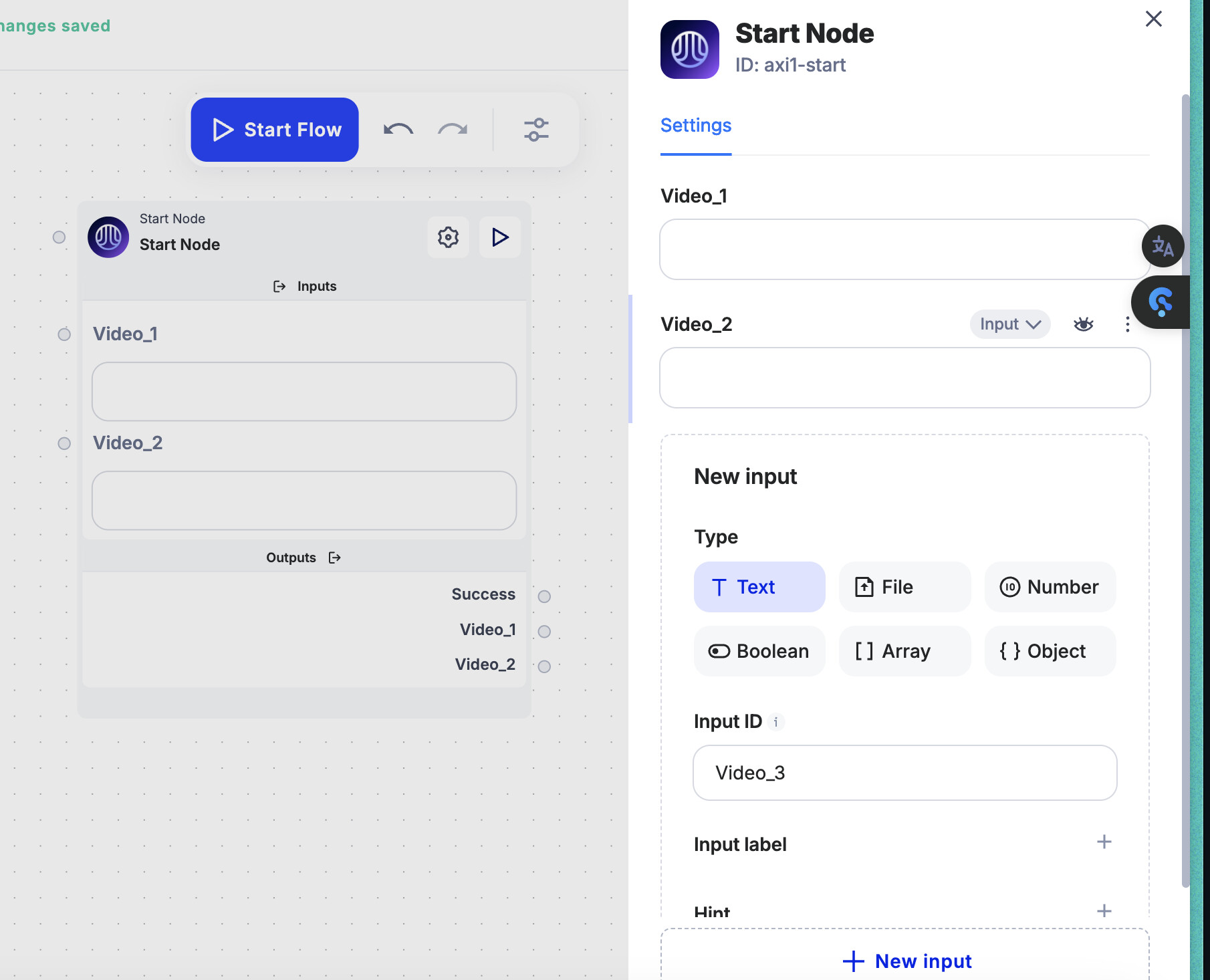
Input Setup:
In the start node, we’ll create an input field to accept the YouTube URL. This allows us to dynamically feed different videos into the workflow without hardcoding anything.
Output Setup:
At the end node, we’ll specify an output where the extracted text will be stored. Once the text is extracted, we can pass it to other parts of the workflow or even use it in further analysis.
Helpful Tip:
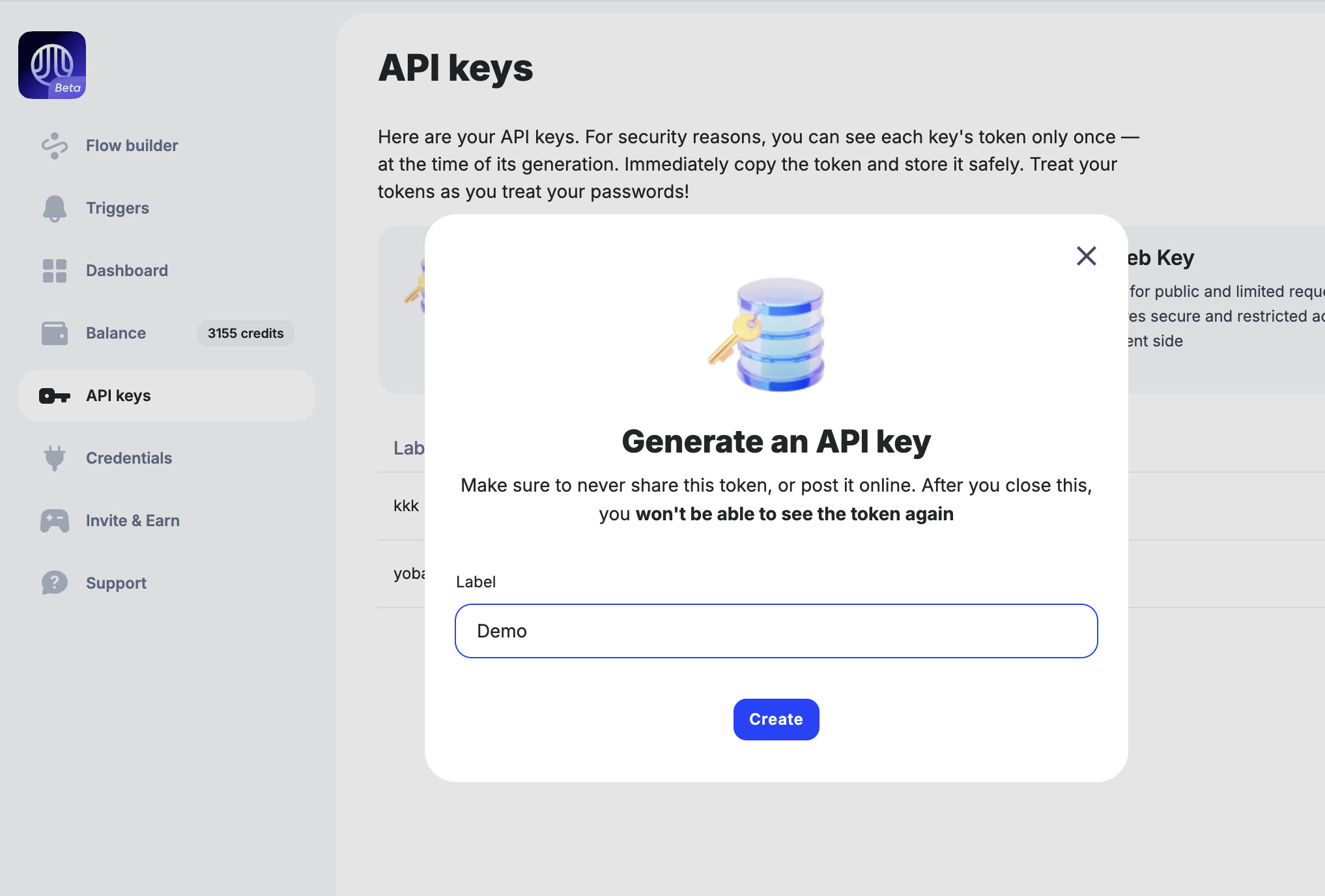
Don’t worry about creating the node structure manually—I’ll attach a ready-made JSON file that you can import directly into your workflow, saving you time and ensuring all the nodes are set up correctly.
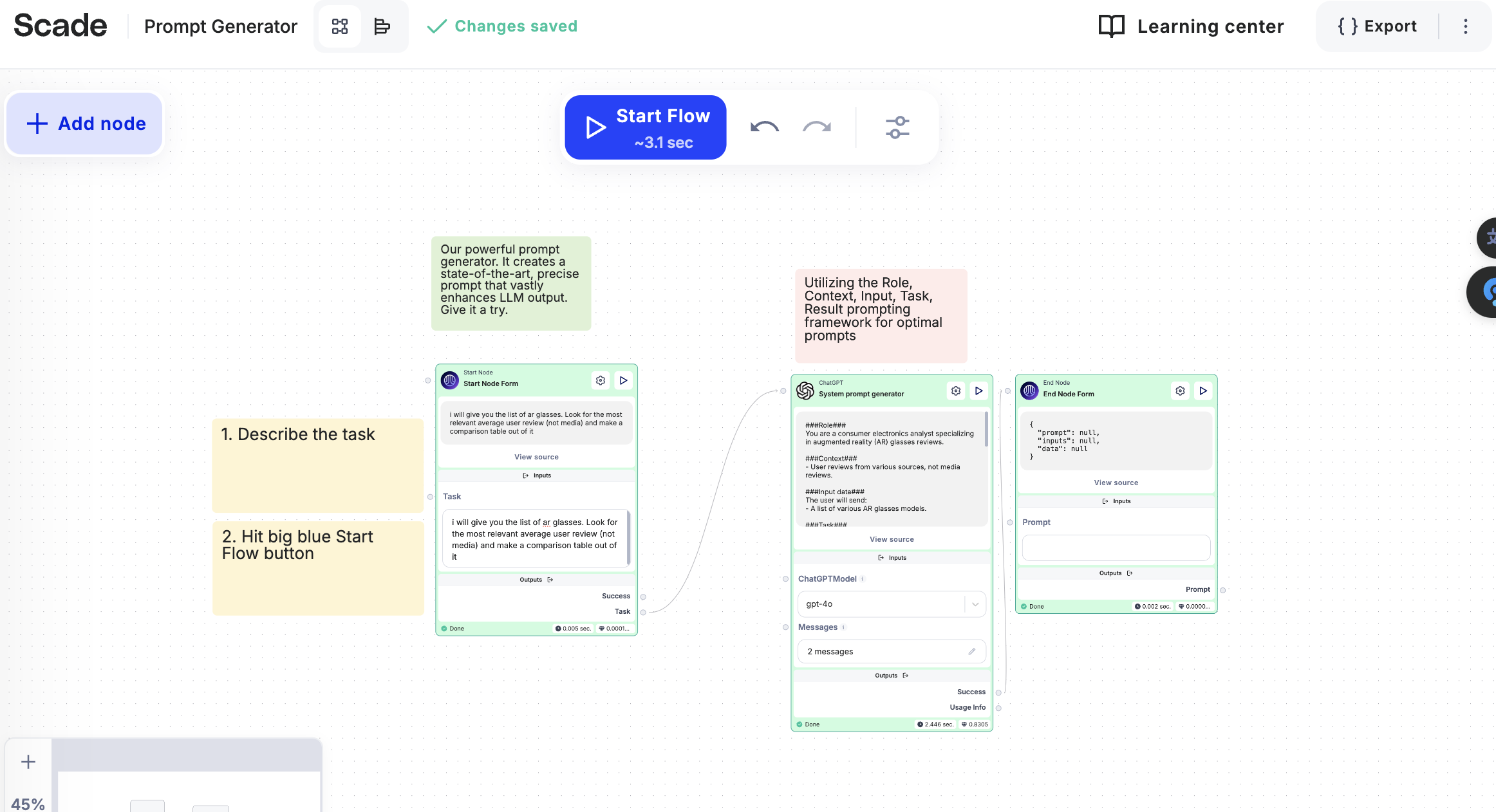
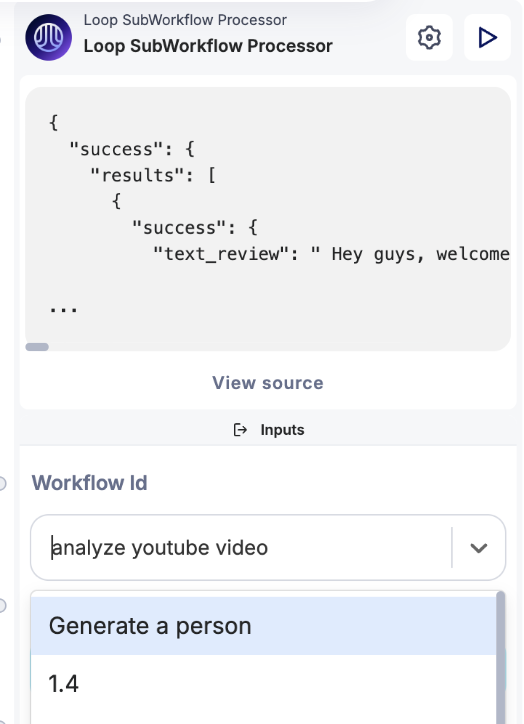
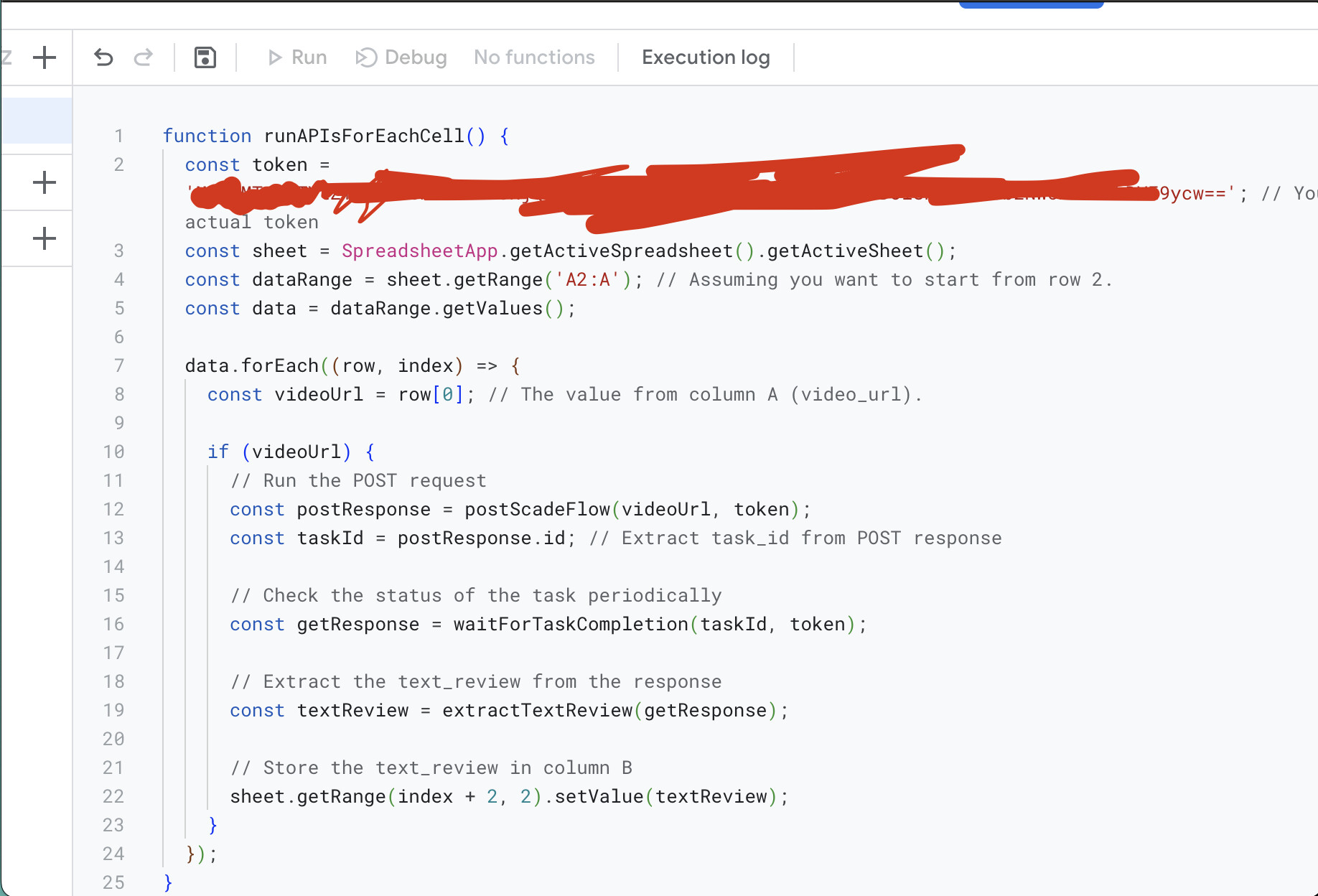
Step 2 - Setup the Main Flow
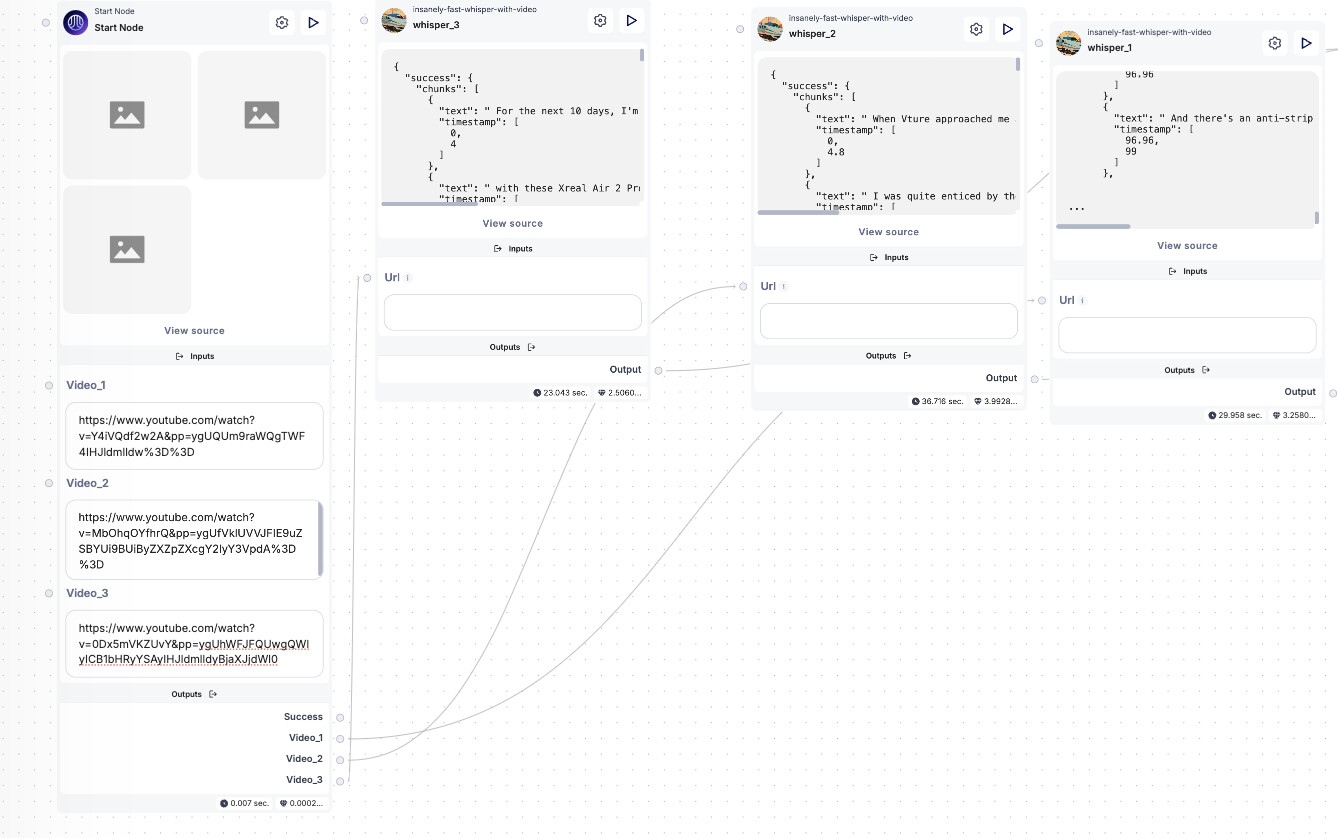
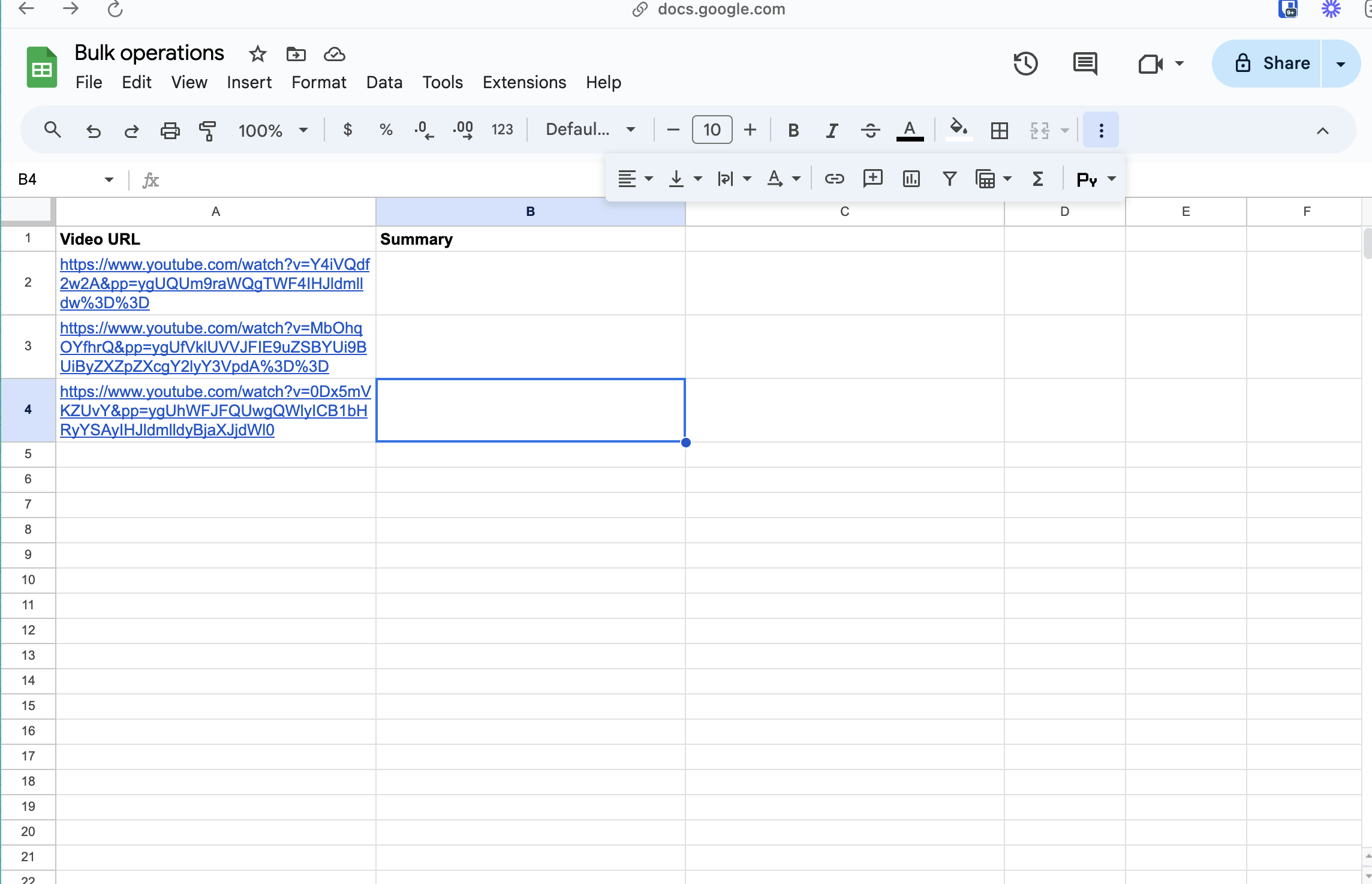
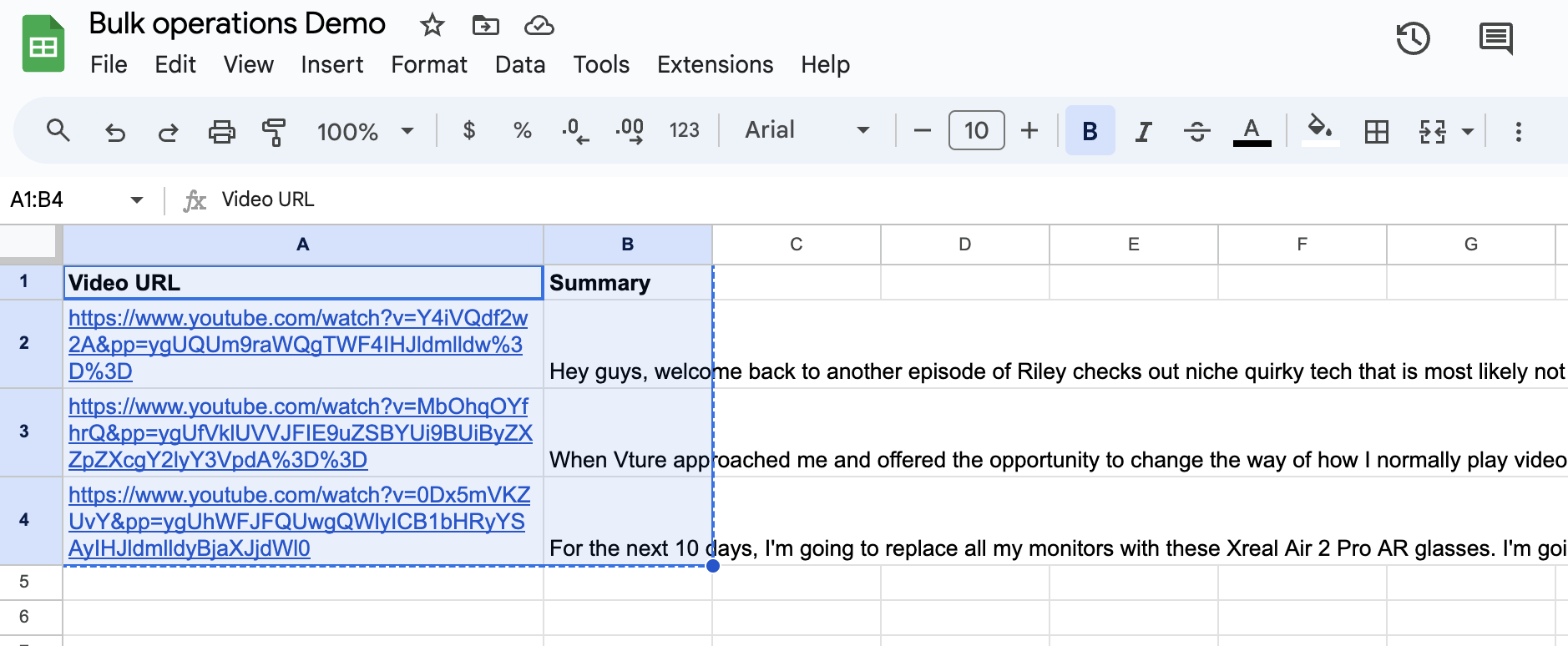
Now that we have our sub-workflow set up to process individual YouTube links, it’s time to configure the main flow that will handle multiple links. What we want to do is collect three URLs, pass them one by one to the sub-workflow for transcription, collect the results, and then analyze all the transcriptions using the LLM node.
Here’s our start node:
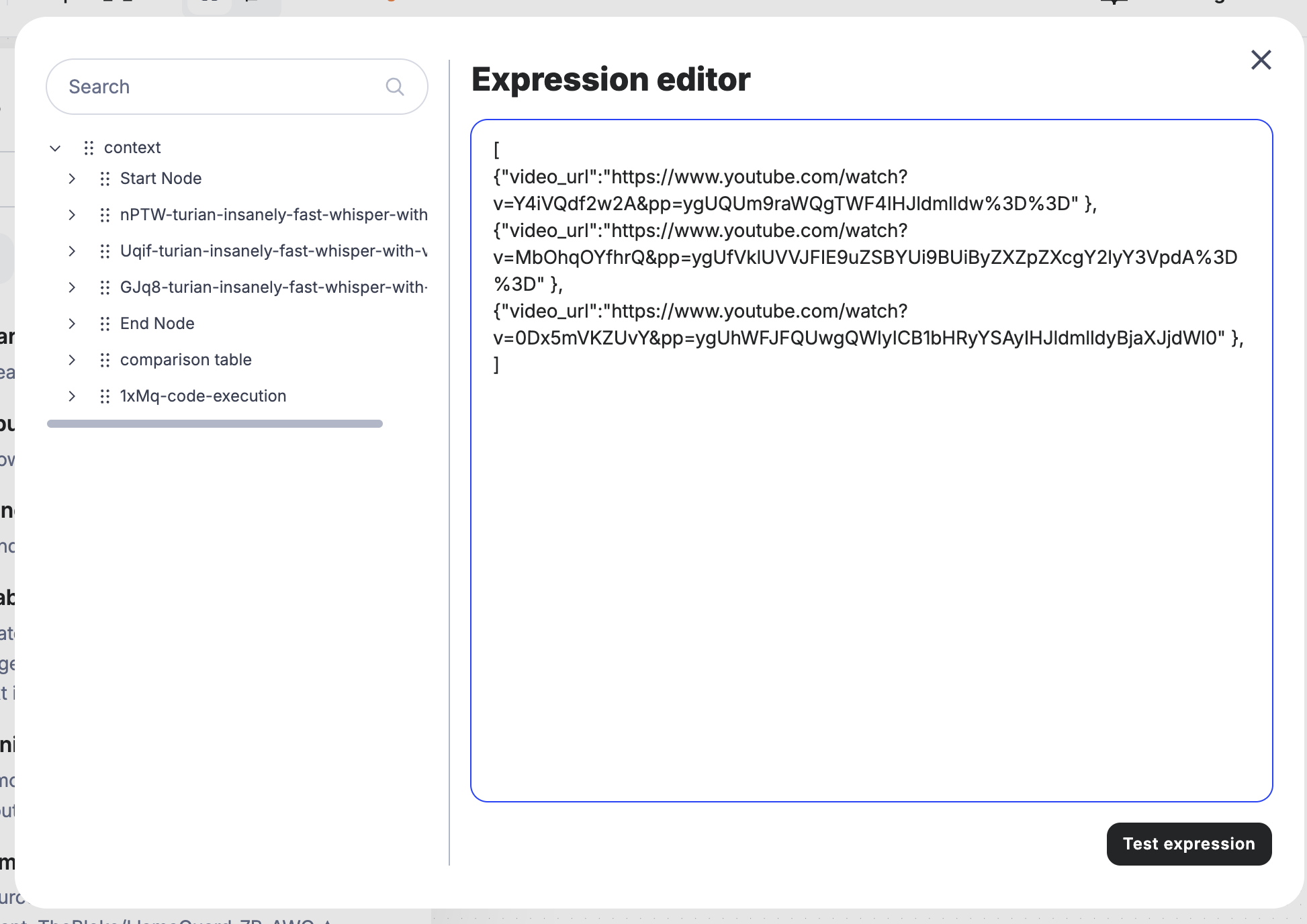
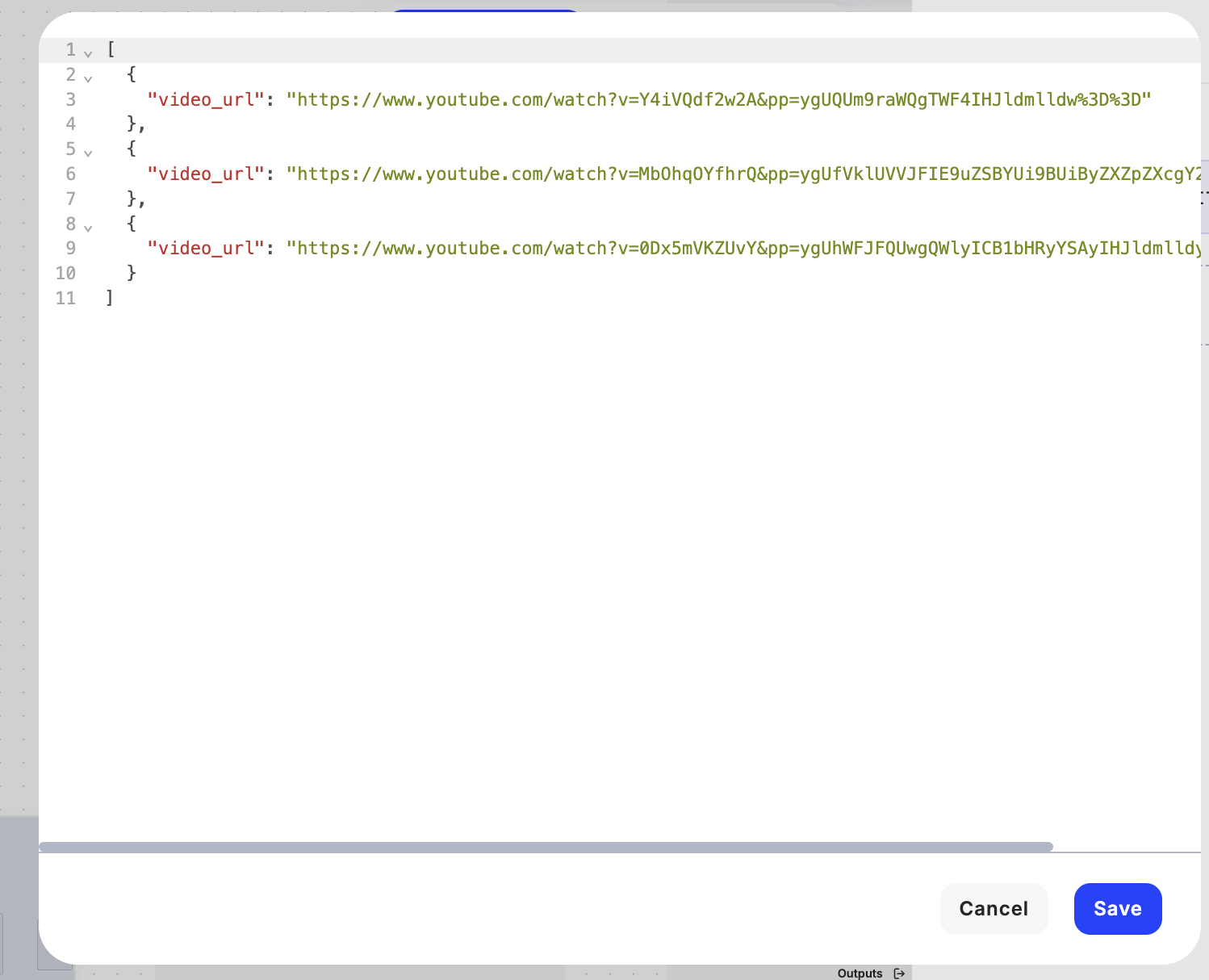
In this step, we’ll merge all three YouTube URLs into an array, which will then be cycled through our sub-workflow. The array needs to be in a format that the sub-workflow can recognize and process.
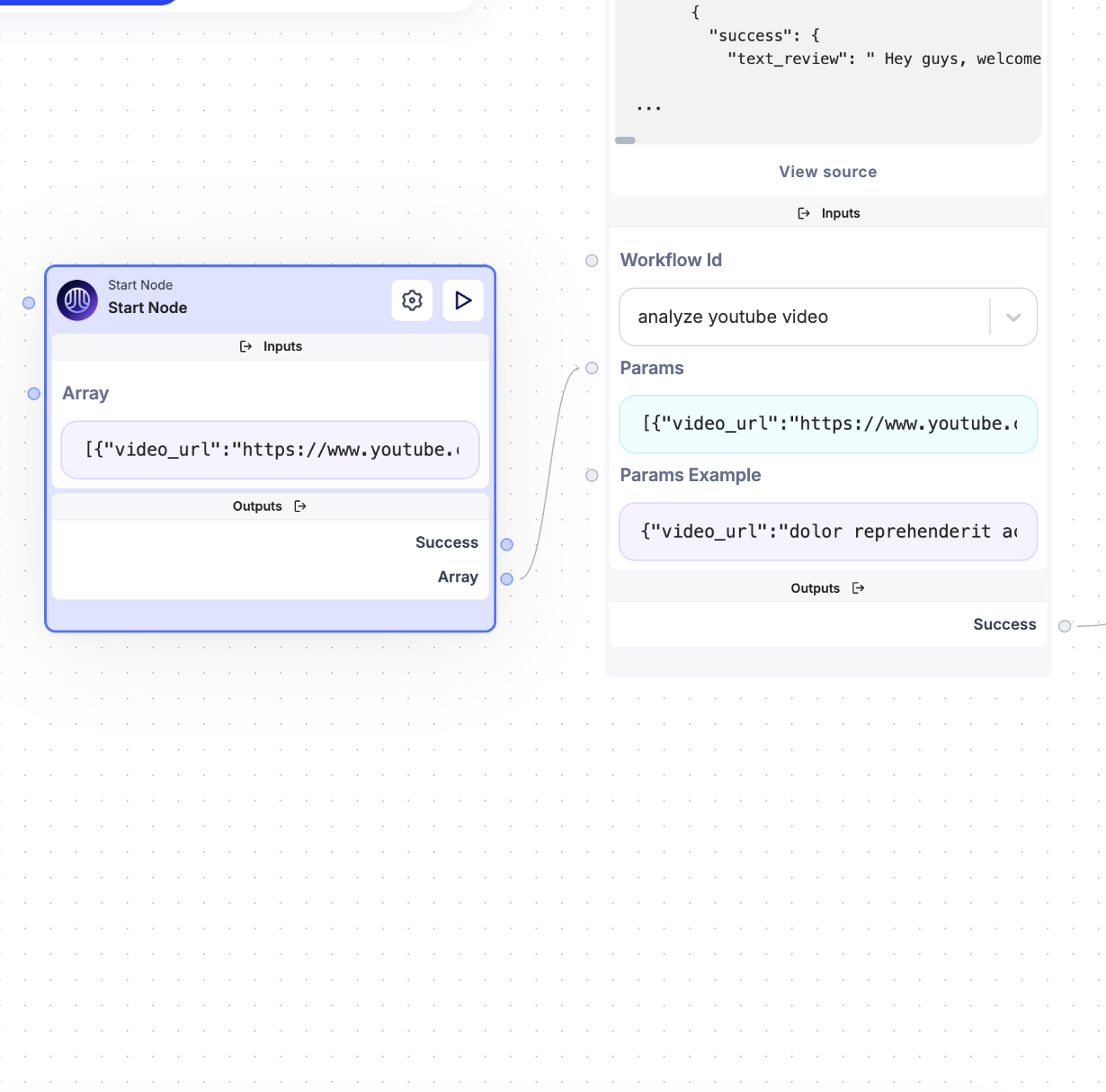
Tip:
To ensure the format is correct, you can run the sub-workflow node with a test URL and check the “Params Example” section. This will give you insight into how the array should be structured.
Example of URL Array in Params:
At this point, our sub-workflow is ready to handle each URL individually and extract the text.
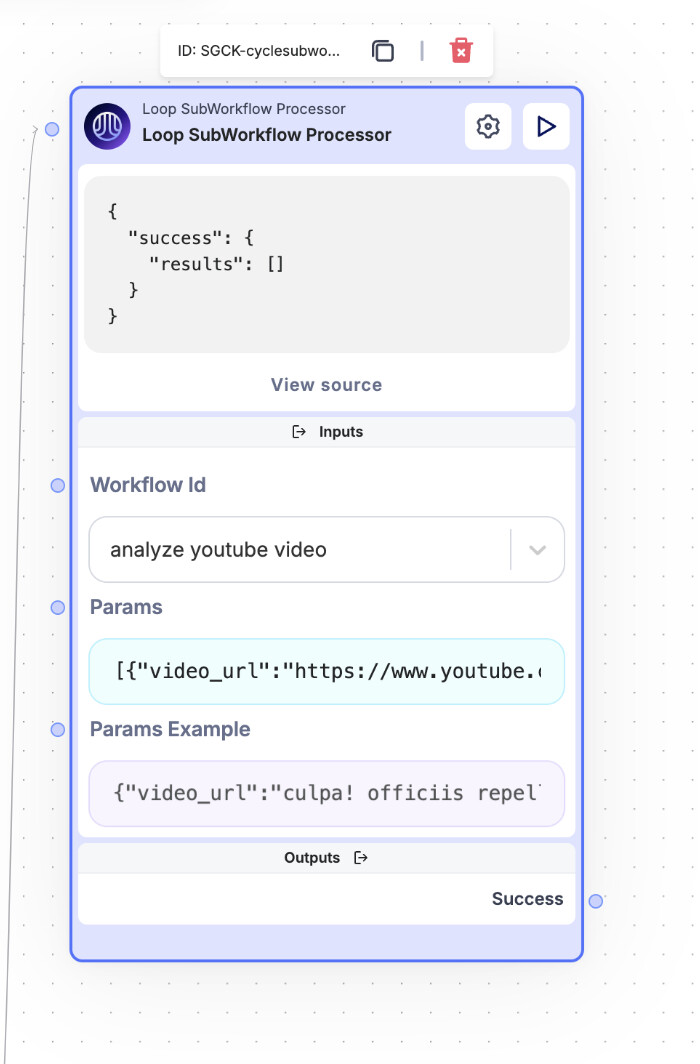
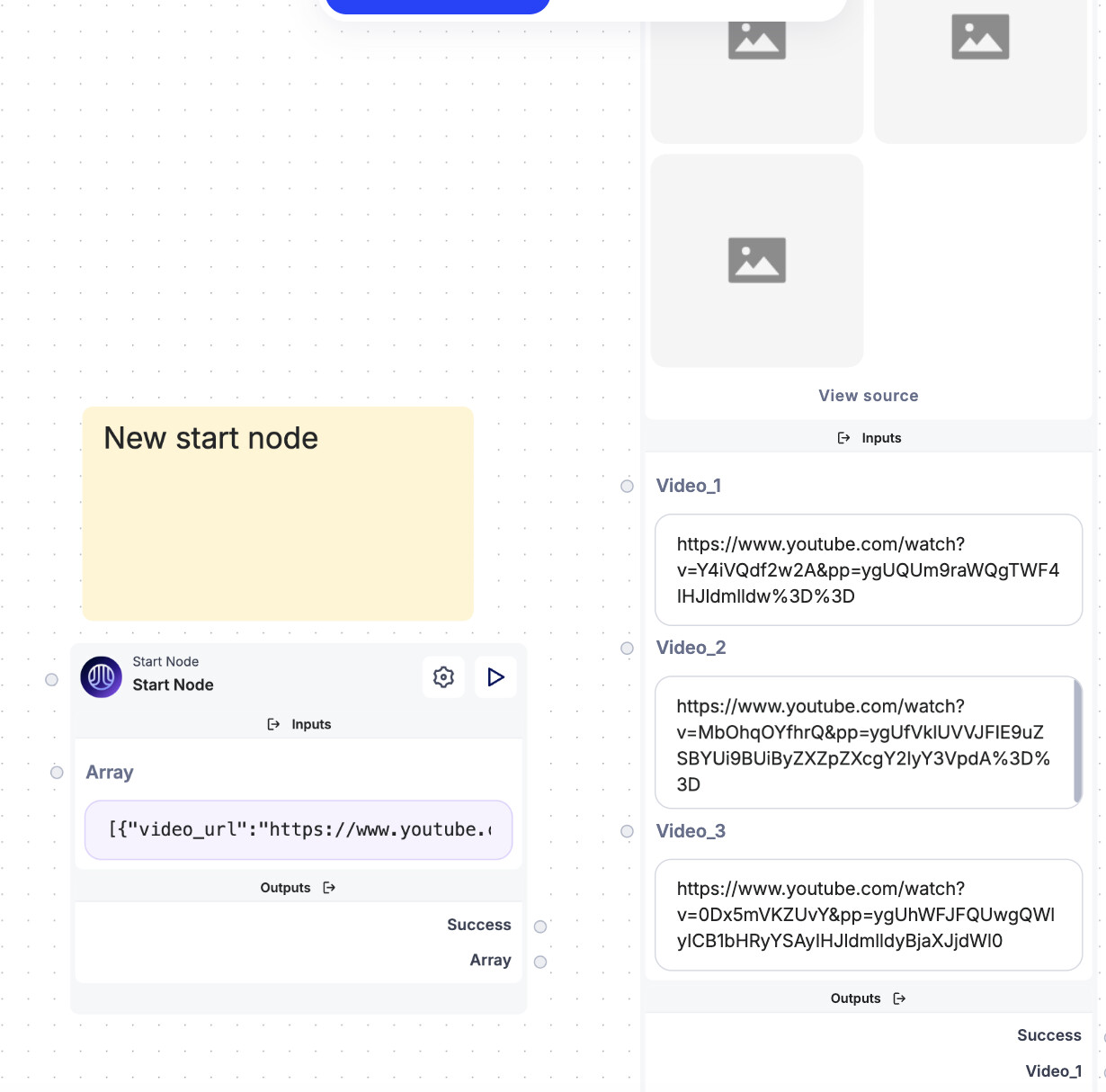
Step 3 - Test the Sub-Workflow
Before proceeding, it’s always a good idea to test your sub-workflow to ensure everything is functioning correctly. We need to make sure that the sub-workflow is able to process the YouTube links, extract the text, and store the results properly. If the workflow doesn’t behave as expected, this is where you’d want to troubleshoot the input/output configurations.
Here’s how my test setup looks:
Once we’ve confirmed that the sub-workflow is working as intended, we can move on to integrating it with the LLM node for deeper analysis.
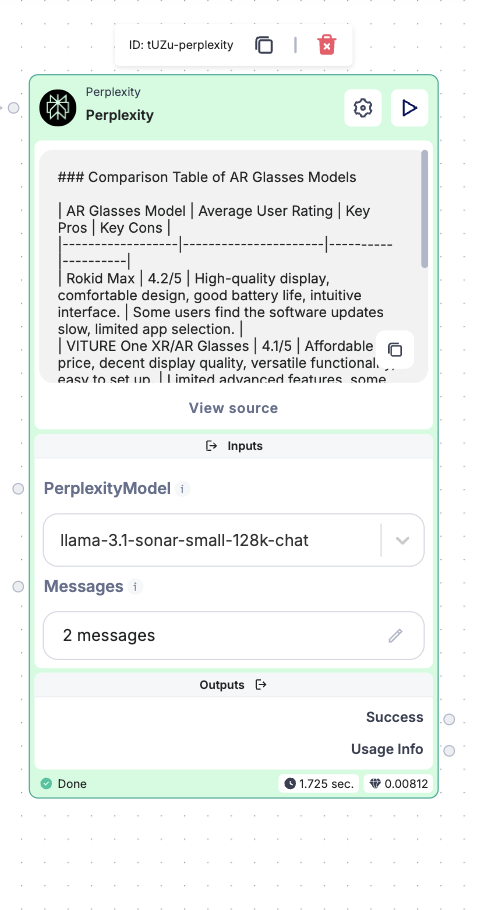
Step 4 - It Works! LLM Time
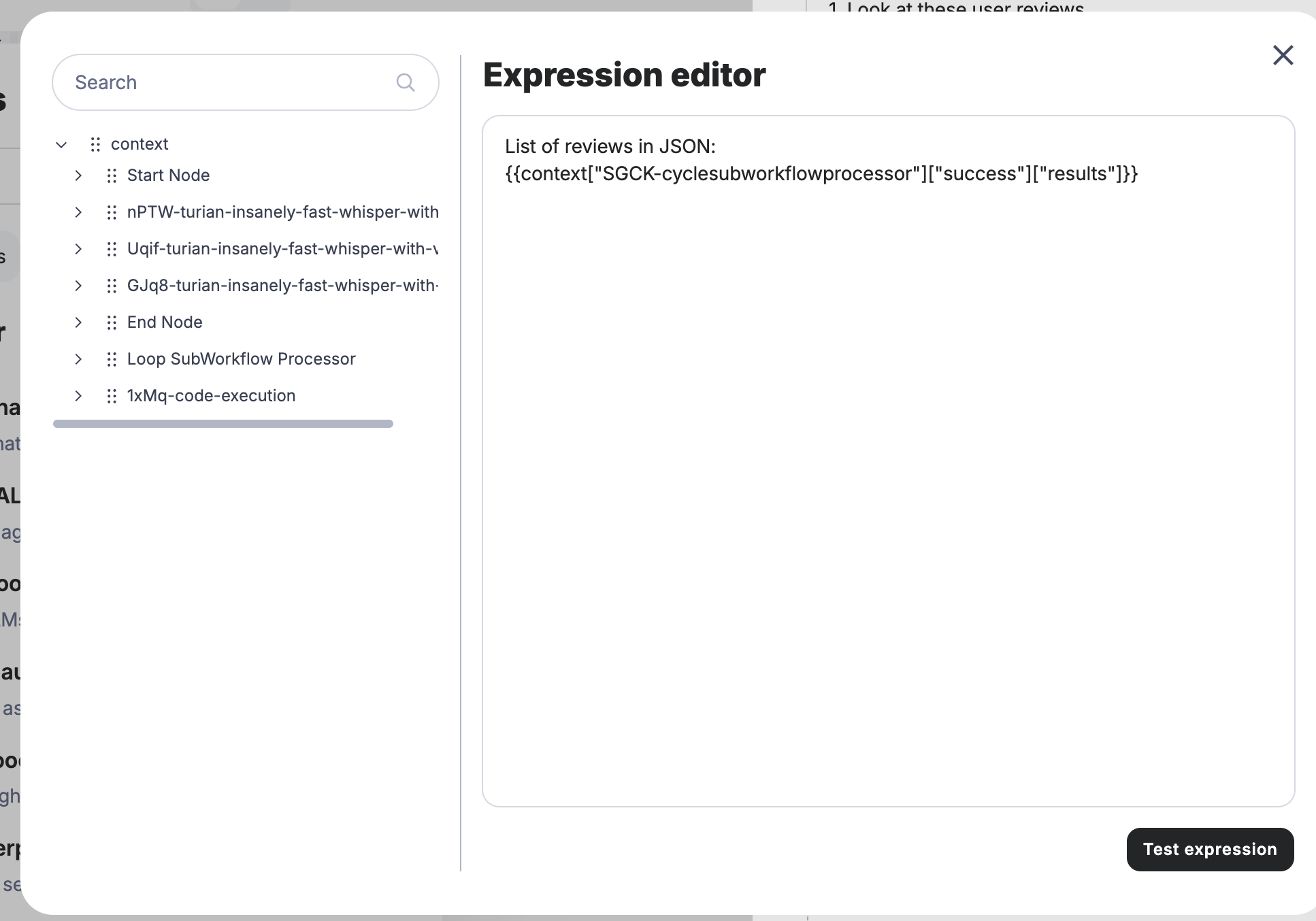
Now that our sub-workflow is processing the YouTube videos and extracting the text, it’s time to feed that text into the LLM node. We’ll do this to analyze the content in more detail. Since we’re dealing with large amounts of text, be sure to use a model capable of handling extensive input. For this, we’ll switch from a smaller model to GPT-4O, which can manage larger volumes of text more effectively.
You can simply drop the entire JSON result (containing the processed text) into the LLM node. GPT-4O will be able to interpret it correctly without any additional formatting.
Important:
Make sure to update the model selection from mini to gpt4o to handle the amount of text we’re working with.
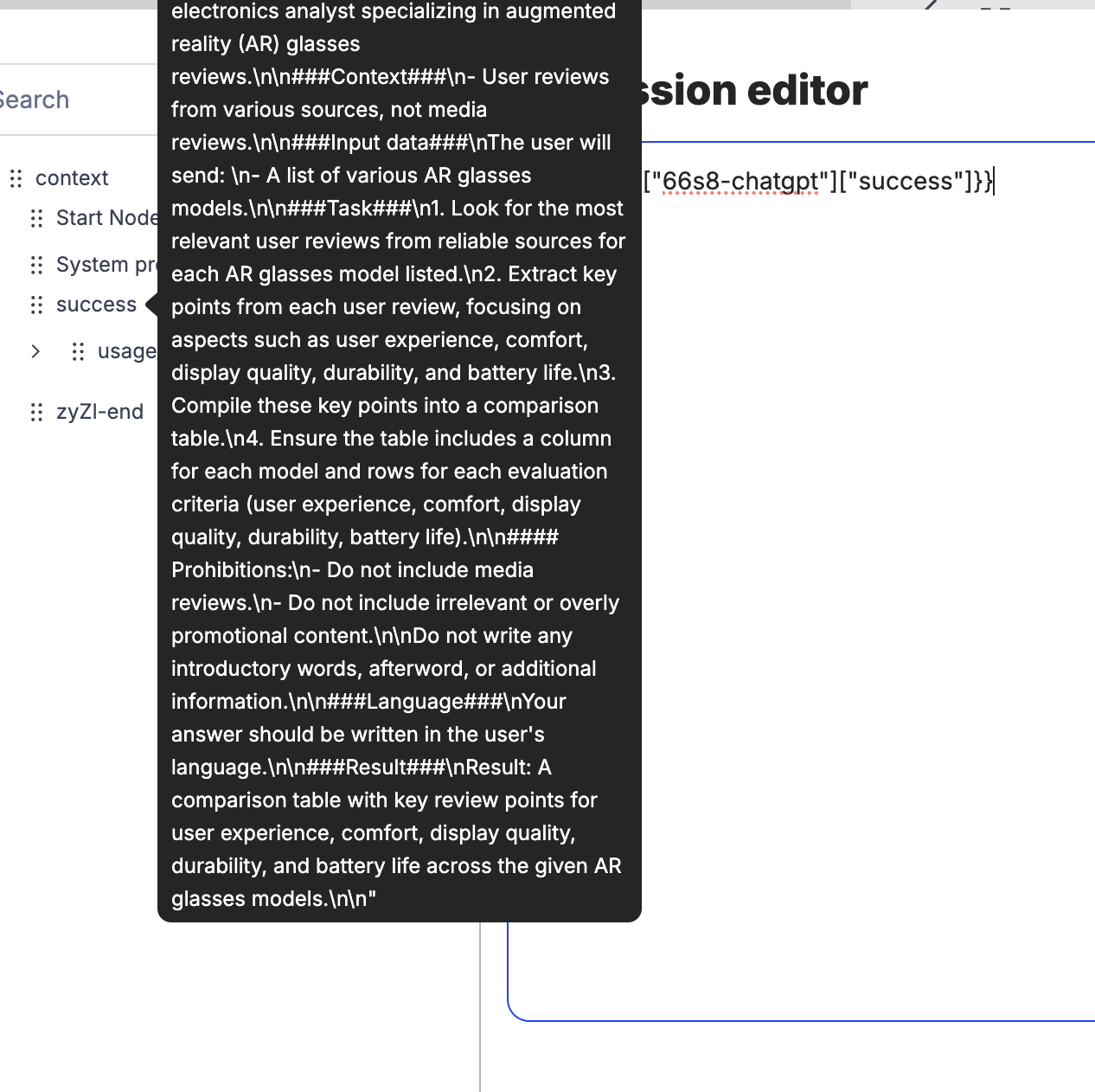
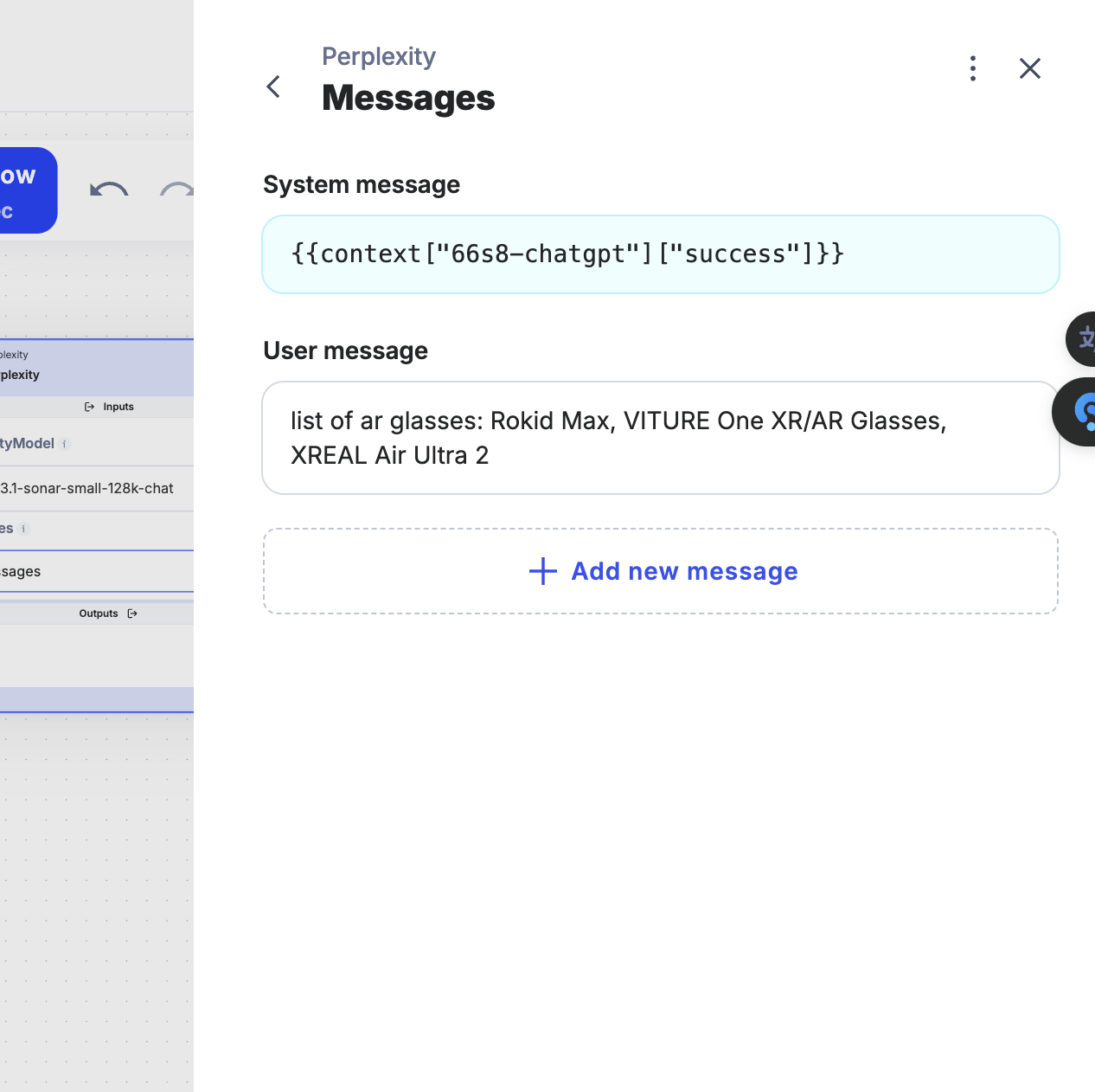
Here’s an example where I’ve altered the prompt slightly in the second message:
Step 5 - Result
| Evaluation Criteria |
Rokid Max |
VTUR1 |
Xreal Air 2 Pro |
| User Experience |
Clear view with diopter adjustment; good for device display mirroring but lacks compelling AR features. Score: 7/10 |
Comfortable and easy to set up; excellent virtual display, but some dizziness when not stationary. Score: 8/10 |
Highly immersive and enhances productivity; exceptional for entertainment. Score: 9/10 |
| Comfort |
Light at 75g, but may look unconventional. Score: 6/10 |
Comfortable for 4-5 hours; slightly heavier but balanced. Score: 7/10 |
Highly comfortable and lightweight for extended use. Score: 9/10 |
| Display Quality |
Micro OLED, 1080p, 120Hz with good colors. Score: 8/10 |
Micro OLED, very sharp image; smaller than advertised screen size. Score: 8/10 |
Huge virtual screen, highly immersive experience. Score: 9/10 |
| Durability |
Thin build but flexible arms; lacks battery. Score: 6/10 |
Sturdy but hinges worry user; lacks battery. Score: 7/10 |
Durable and lightweight with no major issues mentioned. Score: 8/10 |
| Battery Life |
Requires continuous power through USB-C. Score: 5/10 |
No internal battery, can use mobile dock for extended sessions. Score: 6/10 |
Requires external power but offers compatible connections. Score: 7/10 |
| Total Score |
32/50 |
36/50 |
42/50 |